
How underwriting document handling works in 2026

Underwriting is often described as a decision-making process, but the less visible truth is that how underwriting document handling works determines whether those decisions are fast, defensible, and compliant. The formal term for this discipline is underwriting document management, and it covers everything from the moment a submission lands in an inbox to the point where a file is archived and audit-ready. Get it wrong and you face delays, regulatory exposure, and decisions that cannot be defended. Get it right and the entire underwriting workflow accelerates without sacrificing accuracy.
Table of Contents
- Key takeaways
- How underwriting document handling works: the core documents
- The document handling pipeline from intake to routing
- Automation in underwriting document handling
- Compliance, audit readiness, and retention
- Practical tips for managing underwriting documents
- My view on where this is all heading
- Take the next step with Docpolish
- FAQ
Key takeaways
| Point | Details |
|---|---|
| Document types drive risk decisions | ACORD forms, loss runs, schedules, and third-party checks each answer specific underwriting questions about exposure and history. |
| Intake is the critical bottleneck | Inconsistent submission formats at intake cause the most downstream delays and re-keying errors in the workflow. |
| Automation complements judgement | AI handles classification, extraction, and validation so underwriters can focus on genuine risk analysis rather than data entry. |
| Audit readiness starts at intake | Building version control and evidence linkage from day one protects against regulatory findings and supports defensible decisions. |
| GDPR constrains retention | Personal data in underwriting files must have documented retention periods and deletion procedures under Article 5(1)(e). |
How underwriting document handling works: the core documents
Before you can optimise any workflow, you need to understand what is actually moving through it. Underwriting document management begins with a defined set of document types, each of which answers a specific question about the risk being assessed.
The standard documents in commercial underwriting include:
- ACORD forms (such as ACORD 125 for commercial accounts and ACORD 140 for property): these provide the baseline application data covering insured details, business description, and coverage requests.
- Schedules: driver lists, vehicle registers, and payroll schedules quantify the exposures attached to the risk. A missing driver schedule on a fleet account is not a minor gap; it makes accurate rating impossible.
- Loss runs: loss runs often span three to five years across multiple carriers with inconsistent formats, arriving as spreadsheets, PDFs, or typed letters. Mapping them accurately requires careful version control.
- Prior carrier information: cancellation notices, non-renewal letters, and prior policy declarations reveal coverage gaps and underwriting history that loss runs alone do not capture.
- Third-party reports: Motor Vehicle Records (MVRs), credit reports, inspection reports, and sanctions checks provide independent verification of what the applicant has declared.
Each document type addresses a distinct underwriting question. Loss runs answer “what has gone wrong before and how much did it cost?” MVRs answer “are the drivers who they claim to be and what is their record?” ACORD forms answer “what is the risk and what coverage is being requested?” Format variability across these documents is one of the most persistent challenges in document handling in underwriting. A loss run from one carrier looks nothing like one from another, yet both must feed the same data fields in your underwriting system.
Version control compounds the problem. When a broker resubmits a corrected schedule two days after the original, the underwriting file must reflect which version was used for the decision and why the earlier one was superseded. Without that discipline, audit defence becomes guesswork.
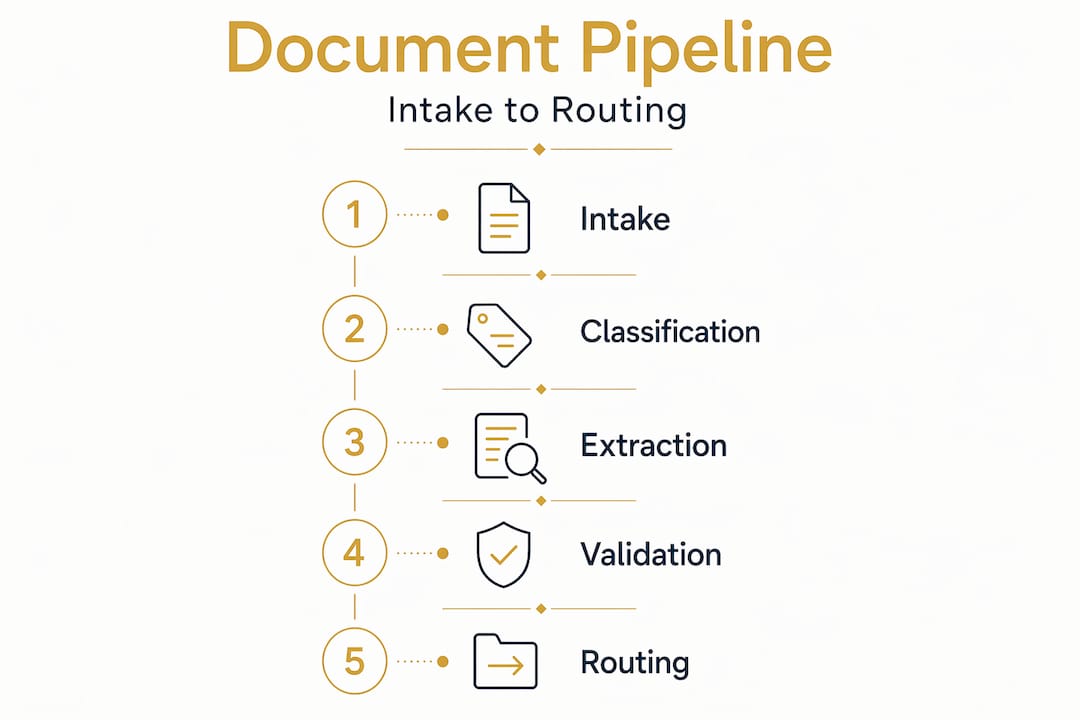
The document handling pipeline from intake to routing
The steps in underwriting document review follow a logical sequence, but each stage carries its own failure modes. Understanding the full pipeline is what separates teams that process submissions efficiently from those permanently buried in queries.
-
Intake: Submissions arrive via email, broker portals, API feeds, and occasionally post. Inconsistent submission formats and manual triage are the primary bottleneck at this stage, causing re-keying and slow decision starts. A submission labelled “New Business” in the subject line may contain renewal documents, mid-term endorsements, or a mix of both.
-
Classification: Each document in the submission is identified and categorised. Is this a loss run or a schedule? Is this the current ACORD form or a version from three years ago? Classification logic determines which extraction method applies downstream.
-
Extraction: Once classified, structured data is pulled from each document. OCR and AI-based extraction tools handle this at scale, but the quality of extraction depends entirely on classification accuracy. Confidence-aware field extraction flags uncertain or unreadable fields with null returns rather than guessing, which reduces governance risk significantly.
-
Validation: Extracted data is checked against business rules and cross-document consistency. Does the driver count on the ACORD form match the driver schedule? Does the declared payroll align with the prior year’s figures? Validation catches discrepancies before they reach the underwriter.
-
Routing: Based on validation outcomes, the submission follows one of three paths: straight-through processing for clean, complete submissions; referral to an underwriter for cases requiring judgement; or decline where eligibility criteria are not met.
Pro Tip: Treat the routing decision as a data output, not a manual step. If your validation logic is precise enough, routing criteria can be applied automatically, reserving underwriter time for genuine risk complexity rather than administrative triage.
Manual re-keying between stages is where most operational time is lost. When data extracted from a loss run must be typed into a rating system by hand, you introduce both delay and transcription error. The underwriting automation pipeline covering intake, classification, extraction, validation, and routing exists precisely to eliminate those manual handoffs.

Automation in underwriting document handling
The case for automation in underwriting documentation requirements is not about replacing underwriters. It is about removing the work that should never have been theirs in the first place.
AI and machine learning contribute at four distinct points in the workflow:
- Classification: Models trained on historical submissions can identify document types with high accuracy, even when filenames are unhelpful or documents are bundled into single PDFs.
- Extraction: AI extraction handles structured and semi-structured documents, pulling named fields from ACORD forms and inferring field values from unstructured loss run narratives.
- Validation: Rule-based engines cross-check extracted values against underwriting guidelines, prior submissions, and third-party data sources in seconds rather than minutes.
- Routing: Automated routing logic applies eligibility and referral criteria consistently, without the variation that comes from individual triage decisions.
The time and accuracy benefits are real. Automation accelerates manual underwriting tasks, allowing underwriters to focus on complex risk evaluations rather than data entry. That shift in focus matters because underwriting judgement, the part that assesses whether a risk is desirable at a given price, cannot be automated. What can be automated is everything that feeds that judgement.
Pro Tip: The biggest efficiency gains from automation come not from the extraction stage but from early classification and validation at intake. Early classification during intake provides the greatest leverage in reducing underwriting cycle times, because errors caught at intake cost far less to fix than errors caught after a referral.
The practical consideration most teams underestimate is integration. Automation tools need to connect with your policy administration system, your rating platform, and your document repository. A classification model that cannot write its output to the right system creates a new manual step rather than eliminating one.
Compliance, audit readiness, and retention
The importance of underwriting documentation becomes most apparent when a regulator asks you to defend a decision made eighteen months ago. If your file is a folder of unlabelled PDFs with no version history, that conversation will not go well.
Audit-ready document handling is not something you retrofit after a review. It is a design choice made at the intake stage.
| Practice | Poor approach | Audit-ready approach |
|---|---|---|
| Version control | Files overwritten silently | Final versions locked, drafts archived with timestamps |
| Evidence linkage | Decisions recorded without source documents | Each decision linked to the specific document version that supported it |
| File structure | Flat folder with mixed document types | Labelled sections: documents received, communications, decisions |
| Metadata | None | Date, author, document type, completeness status on every item |
| Retention policy | Ad hoc | Documented schedule per data category, aligned to regulatory requirements |
Professional underwriting recordkeeping recommends retaining records three to six years, covering applications, reports, guidelines, correspondence, and decision documents. That is a minimum, not a target. Reinsurance files and credit investigations often carry longer requirements.
GDPR adds a further constraint for any file containing personal data. Article 5(1)(e) mandates keeping personal data no longer than necessary, with documented retention periods and explicit deletion or anonymisation procedures per data category. An underwriting file containing a named individual’s MVR or credit report is subject to that obligation. Retention and deletion must be planned, not improvised.
Audit-ready automation treats document handling as a continuous workflow with tight evidence-to-condition linkages, not a series of disconnected steps. That framing matters because regulators do not assess individual documents in isolation. They assess whether the file, taken as a whole, supports the decision recorded.
Practical tips for managing underwriting documents
Improving how you manage underwriting documents does not require a full technology overhaul. Several practices deliver measurable gains with modest investment.
- Build self-explanatory file structures: Labelled sections with metadata covering date, author, and description make files legible to anyone who opens them, including an examiner who has no prior context.
- Apply cross-document validation as standard: Compare driver lists against loss runs, declared payroll against prior year figures, and vehicle counts against fleet schedules. Inconsistencies caught before underwriter review reduce back-and-forth with brokers significantly.
- Track NIGO rates: “Not In Good Order” rates measure the proportion of submissions arriving with missing or deficient documents. Tracking this by broker and document type identifies where broker education or submission templates would reduce friction.
- Set turnaround KPIs by document stage: Measuring time from intake to classification, classification to extraction, and extraction to underwriter review reveals where the pipeline is slow. Without stage-level metrics, you cannot distinguish a classification problem from a validation problem.
- Minimise broker queries through upfront checklists: A submission checklist aligned to your underwriting documentation requirements, sent to brokers before submission, reduces the volume of incomplete files arriving at intake.
The underwriting document management tips that make the most difference are the ones that address the root cause of delay, which is almost always missing information discovered late in the process.
My view on where this is all heading
I have watched teams invest heavily in AI extraction tools while leaving their intake process entirely manual. The result is a fast extraction engine fed by slow, inconsistent input. That mismatch is the most common implementation mistake I see.
Document handling in underwriting is not a problem that automation solves wholesale. It is a problem that automation solves in layers, starting at intake and working downstream. The teams getting the best results are those who treated audit readiness as a design requirement from the beginning, not as a compliance checkbox added after the fact.
What I find genuinely interesting about 2026 is that the technology to handle most of this well now exists and is accessible to mid-sized insurers, not just the large carriers. The constraint is no longer capability. It is the willingness to redesign workflows rather than automate broken ones.
Underwriters who understand the document pipeline are better underwriters. Not because they need to manage documents themselves, but because they understand what the data they are working with has been through and where its limitations lie.
Take the next step with Docpolish
The compliance pressures described in this article do not stop at document organisation. Every underwriting file that passes through a review or polishing process carries personal data, and that data needs protecting before it touches any external tool.
Docpolish is built specifically for regulated industries. It detects and anonymises PII directly in the browser before any text reaches the AI engine, then restores the original entities in the polished output. Raw personal data never leaves your environment. If your team is working with underwriting documents that contain named individuals, policy references, or financial details, try Docpolish to see how privacy-first document polishing fits into your existing workflow without adding compliance risk.
FAQ
What documents are required in underwriting?
Standard underwriting documentation requirements include ACORD application forms, loss runs covering three to five years, driver and vehicle schedules, prior carrier information, and third-party reports such as MVRs and credit checks. The specific set varies by line of business.
How long should underwriting records be retained?
Professional guidance recommends retaining underwriting records for three to six years, covering applications, risk assessment evidence, correspondence, and decision documents. GDPR requires documented retention periods for any files containing personal data, with explicit deletion or anonymisation procedures.
What is a NIGO rate in underwriting?
NIGO stands for “Not In Good Order” and measures the percentage of submissions arriving with missing or deficient documents. Tracking NIGO rates by broker and document type is one of the most practical underwriting document management tips for identifying where submission quality needs to improve.
How does automation improve underwriting document review?
Automation handles classification, OCR extraction, validation against business rules, and routing decisions, removing manual data entry from the workflow. The steps in underwriting document review that benefit most from automation are early classification and validation at intake, where errors are cheapest to fix.
Why does version control matter in underwriting files?
Version control prevents silent overwrites and preserves the evidence history that regulators examine during audits. Locking final document versions and archiving drafts with timestamps means every decision can be traced to the specific document version that supported it.